The Factors That Drive
Property Prices
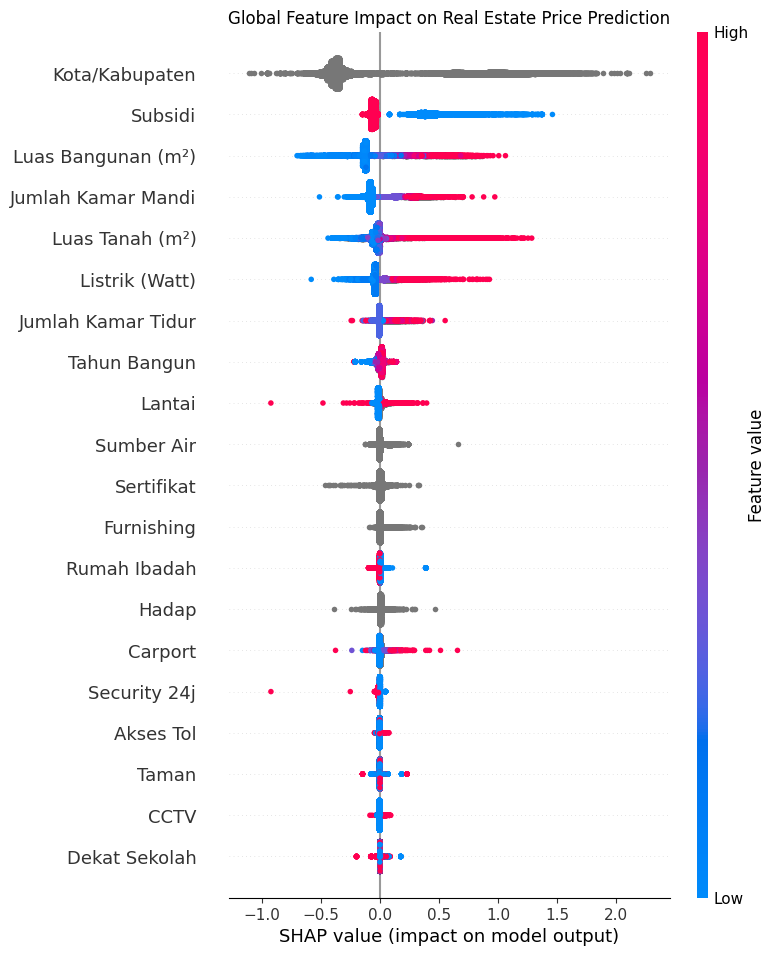
SHAP (SHapley Additive exPlanations) was applied to the trained XGBoost model to produce global feature impact insights. Each dot on the beeswarm plot represents one property — red indicates a high feature value, blue a low one, and horizontal position shows the direction and magnitude of its impact on the predicted price.
-
1
City / Regency
Location is the strongest driver, since it shows a wide SHAP distribution. This suggests the model has learned significant differences between locations, with some areas strongly increasing or decreasing the prediction.
-
2
Government Subsidy
Subsidy status consistently pushes prices down — subsidized properties carry a strong negative SHAP signal, clearly delineating the affordable housing segment.
-
3
Building Area (m²)
Larger building areas (shown in red) produce consistently positive SHAP values. The relationship is strong and monotonic across the entire dataset.
-
4
Number of Bathrooms
Bathroom count serves as a strong proxy for property quality and luxury tier — more bathrooms reliably translate to higher predicted prices.
-
5
Land Area (m²)
Larger land plots increase property value, particularly relevant in the landed house segment where plot size is a core pricing component.
-
6
Electricity Capacity (Watt)
Higher electrical capacity is associated with higher predicted outcomes.
Global Feature Impact on Real Estate Price Prediction · SHAP Beeswarm Plot