03 — Process Flow
How It Works
The pipeline operates in two distinct phases: an Indexing Phase that runs once to build the knowledge base, and a Query Phase that runs on every user interaction. The diagram below maps to the numbered steps in the process flow diagram.
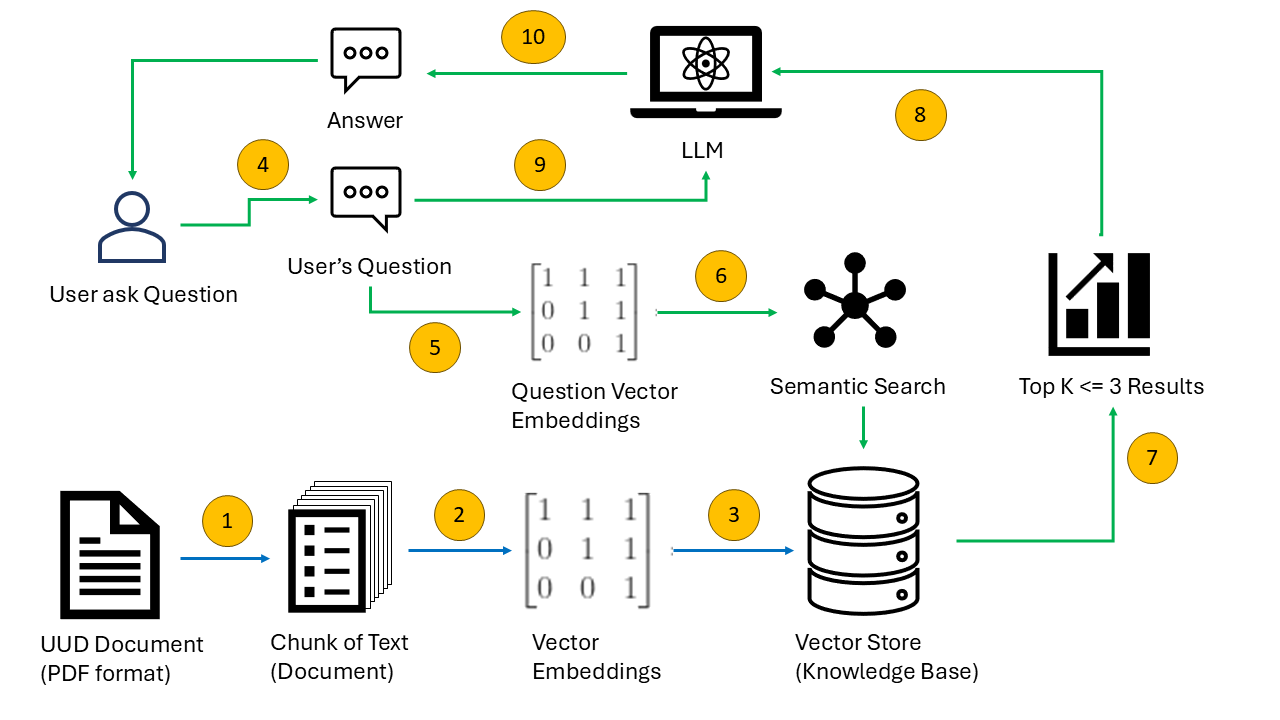
STEP 01
PDF Ingestion & Structured Chunking
PyPDFLoader reads
uud45_asli.pdf page-by-page, extracting raw text with page metadata. The custom parse_uud() function splits text into semantic chunks aligned with legal structure: BAB → Pasal → Ayat.STEP 02
Embeddings
Each chunk is encoded by
all-MiniLM-L6-v2 into an embedding vector.STEP 03
Storing Data
The embedding vectors from Step 2 are stored on disk using ChromaDB.
STEP 04
User Query
User types a natural language question in the Streamlit chat interface.
STEP 05
Query Embedding
The same sentence-transformer model converts the user's question into a vector embedding in real-time.
STEP 06
Semantic Search
Cosine similarity is computed between the query vector and all stored document vectors.
STEP 07
Top-K Retrieval
Up to 3 chunks with similarity score ≥ 0.7 are retrieved. Low-confidence matches are filtered out.
STEP 08
Context Formatting
Retrieved chunks are serialized with their metadata (BAB, Pasal, section type) into a structured context string.
STEP 09
Prompt Assembly
The context and question are injected into the prompt template instructing the LLM to act as a constitutional law expert.
STEP 10
LLM Generation
Llama 3.2 1B generates a grounded answer. The text after "Jawaban:" is extracted and displayed to the user.
Phase A
🗂 Indexing (One-Time)
- Load PDF with PyPDFLoader
- Concatenate pages with page numbers
- Run
parse_uud()to generate Document chunks - Embed chunks using sentence-transformers on CUDA
- Persist vectors to
./dbvia ChromaDB
Phase B
💬 Query (Per Interaction)
- Receive user question from Streamlit UI
- Embed query with same model
- Retrieve top-K docs (threshold: 0.7)
- Format context with BAB/Pasal metadata
- Generate answer with Llama 3.2, stream to UI